
How to clean data in Python
A repeatable 3-step data cleaning framework

Data cleaning is the MOST important step of any analysis. If your data is dirty, you can’t trust any insights or models that you build on that data.
What often surprises me is that data cleaning takes up the most time in any project. What I thought would take 5-10% of the time ends up taking 50-80% of the time.
Data cleaning is necessary for good analysis.
The bright side is that data cleaning can be broken down into a repeatable framework. Specifically, these 3 repeatable phases:
Phase 1: Explore the data
Phase 2: Write code to clean the data
Phase 3: Validate the data was correctly cleaned
Let’s dive into each of these.
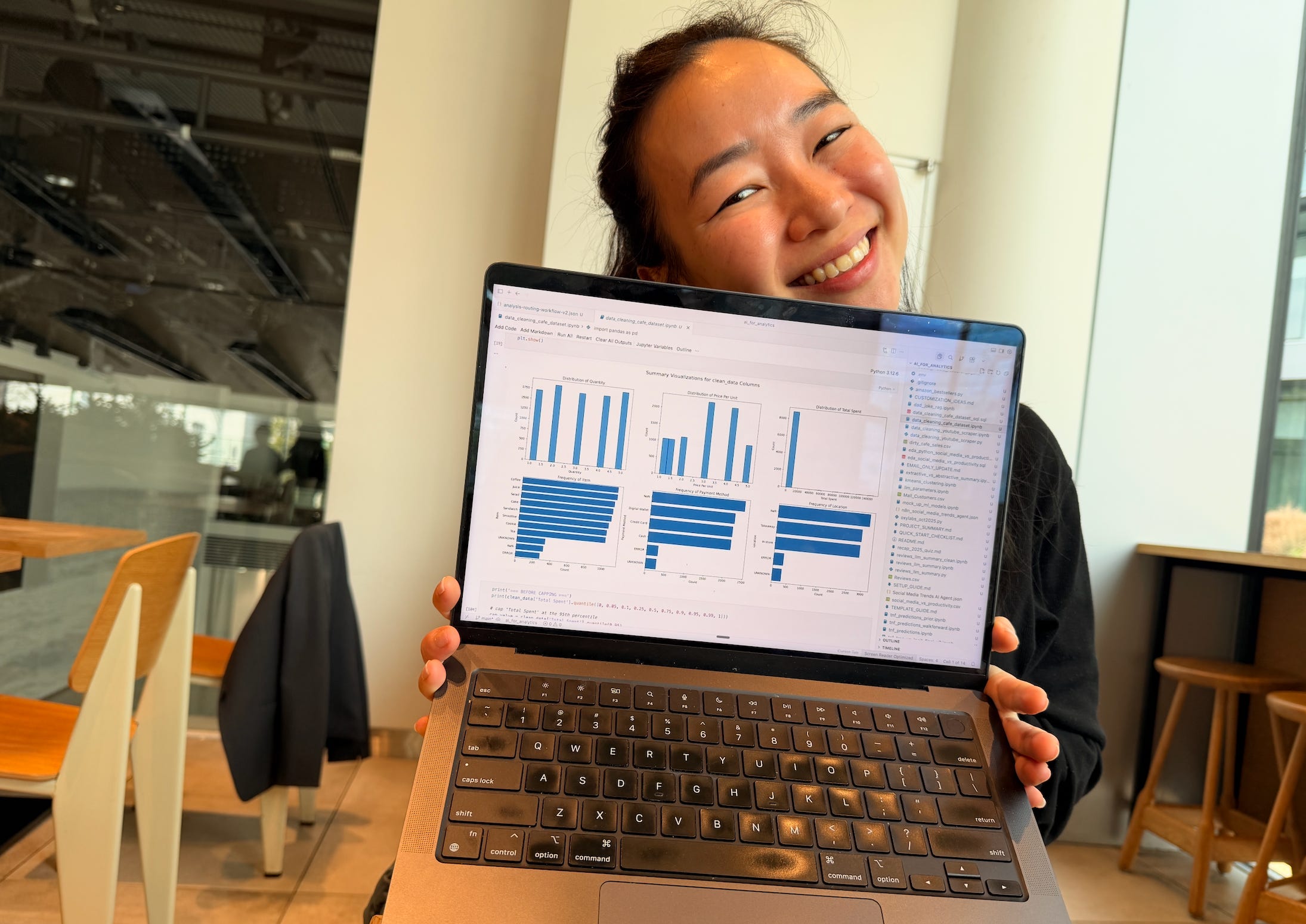
Phase 1: Explore the Data
We need to first understand the state of the data, so we know:
Does the data need to be cleaned?
Which columns need cleaning?
What needs to be done?
I find it helpful to look at the distributions of each column, typically using charts.
We’ll look for missing, unexpected and outlier values.
Python Setup
First, I import the packages I need for data exploration:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsThe steps I take are:
First, I understand my data: what columns I have, whether there is missing data, and what the column types are.
# Load your data
df = pd.read_csv('your_data.csv')
# Get basic information
df.info()
# Check missing values
df.isnull().sum() # Count of missing values per column
df.isnull().sum() / len(df) * 100 # Percentage of missing values
Then I look at summary stats and descriptions. I use the built-in pandas functions
describe()andvalue_counts().
# Numerical columns summary
df.describe() # Shows count, mean, std, min, quartiles, max
# Visualize numerical distributions with histograms
df.hist(figsize=(15, 10), bins=30)
plt.tight_layout()
plt.show()
# For categorical columns
df.describe(include=['object']) # Summary stats for categorical columns
# Visualize categorical distributions with bar charts
categorical_cols = df.select_dtypes(include=['object']).columns
for col in categorical_cols:
plt.figure(figsize=(10, 5))
df[col].value_counts().head(20).plot(kind='bar')
plt.title(f'Distribution of {col}')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()Then I make a list of data cleaning action items in a separate document so I can iterate through that list. It is very helpful to have a list like this, because it’s easy to get lost in the mess of data cleaning, going down rabbit holes… so this list helps keep me on track.
Example action list:
Handle missing values in ‘age’ column
Fix negative sales volumes
Remove outliers in ‘price’ column
Standardize date formats
Phase 2: Clean the Data
Now we know what needs to be cleaned, we can decide how we want to clean the data.
For Missing Values
You can either use various filling techniques or drop the rows altogether.
How to decide which technique to use:
Drop rows when: Missing data is minimal (<5% of dataset) or the rows are corrupted beyond repair
Fill with mean/median when: Data is numerical and roughly normally distributed
Fill with mode when: Data is categorical
Forward/backward fill when: Data has temporal patterns (time series)
Use predictive models when: Missing data is substantial and patterns exist in other columns (this is very time-consuming, so I almost never do this)
## These are different options for filling in missing data. Do NOT run this sequentially.
# Option A: Drop rows with any missing values
df_cleaned = df.dropna()
# Option B: Fill numerical columns with median
df['age'].fillna(df['age'].median(), inplace=True)
# Option C: Fill categorical with mode
df['category'].fillna(df['category'].mode()[0], inplace=True)
# Option D: Forward fill for time series
df['value'].fillna(method='ffill', inplace=True)
For “Unexpected” Values
For unexpected values (like percentages >100% or sales volumes <0), typically drop those rows as that data is corrupted.
Important caveat: Instead of dropping data, you could consider creating a flag column to track corrupted records. This preserves information about data quality issues for future analysis.
# Instead of immediately dropping, create a flag
df['is_corrupted'] = False
df.loc[df['percentage'] > 100, 'is_corrupted'] = True
df.loc[df['sales_volume'] < 0, 'is_corrupted'] = True
# Now you can choose to filter or keep for analysis
df_clean = df[~df['is_corrupted']] # Filter out corrupted
# OR keep everything and use the flag in your analysisFor Outlier Values
Outliers are datapoints (for numerical columns) that do not fall in the typical range of the other columns. I identify outliers using visualizations, typically using histograms to see the overall distribution and boxplots to spot extreme values.
# Visualize outliers with boxplots
numerical_cols = df.select_dtypes(include=[np.number]).columns
fig, axes = plt.subplots(1, len(numerical_cols), figsize=(15, 5))
for i, col in enumerate(numerical_cols):
df.boxplot(column=col, ax=axes[i])
axes[i].set_title(f'{col}')
plt.tight_layout()
plt.show()
# Or use histograms to see distribution shape
for col in numerical_cols:
plt.figure(figsize=(10, 4))
plt.hist(df[col].dropna(), bins=50, edgecolor='black')
plt.title(f'Distribution of {col}')
plt.xlabel(col)
plt.ylabel('Frequency')
plt.show()Once I’ve identified outliers, I use a log-transform or cap/floor the variables.
How to decide which technique to use:
Log transform when: Data is right-skewed and you want to preserve relative relationships (good for prices, incomes, populations)
Capping/flooring when: You want to preserve the original scale but limit extreme values (good for age, scores, ratings)
# Log transform for right-skewed data
df['income_log'] = np.log1p(df['income']) # log1p handles zeros
# Capping and flooring at percentiles
lower = df['price'].quantile(0.01)
upper = df['price'].quantile(0.99)
df['price_capped'] = df['price'].clip(lower=lower, upper=upper)
# Or use z-score for capping
from scipy import stats
df['zscore'] = stats.zscore(df['value'])
df_no_outliers = df[abs(df['zscore']) <= 3]
Hot tip: Use functions to make repetitive cleaning tasks easier. I reuse these functions across all my analyses and models. Or…. build a data cleaning automation tool or agent to save significant time on repeated cleaning tasks across similar datasets.
Phase 3: Validate the Data
Now we validate that data cleaning was done correctly.
I look at before and after charts side-by-side. This makes it easy to visualize the changes made.
# Create before/after comparison
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Before cleaning
axes[0].hist(df_original['price'], bins=30, color='red', alpha=0.7)
axes[0].set_title('Before Cleaning')
axes[0].set_xlabel('Price')
# After cleaning
axes[1].hist(df_cleaned['price'], bins=30, color='green', alpha=0.7)
axes[1].set_title('After Cleaning')
axes[1].set_xlabel('Price')
plt.tight_layout()
plt.show()
# Summary statistics comparison
print("BEFORE CLEANING:")
print(df_original.describe())
print("\nAFTER CLEANING:")
print(df_cleaned.describe())
PS: At this time, you’ll often find more “things” that need to be cleaned. That’s okay and totally normal! Repeat phases 2 and 3 until your data is fully cleaned. The key is to iterate through this process until your data passes all validation checks.
Remember, clean data is the foundation of trustworthy analysis. Data cleaning might feel like it’s take way longer than you thought it would, but trust me, this is a good use of your time!
ICYMI (in case you missed it)
I built a logistic regression model to predict the winner of the Super Bowl
Different AI Agent patterns for Data Science — should I build these out?
Airtable’s new deep research + reporting tool Superagent is Super cool!
What are the most important LLM parameters you must know
Python learning roadmap for Data Scientists
Anyone who smiles based on a post on “how to clean data in python” deserves my respect. 🫡
In some cases, considering the missing value as a new categorical column will also help.